HiER: Highlight Experience Replay
for Boosting Off-Policy Reinforcement Learning Agents





1 Center for Robotics, MINES ParisTech, PSL University, Paris, France
2 Institute for Computer Science and Control, Hungarian Research Network, Budapest, Hungary
3 CoLocation Center for Academic and Industrial Cooperation, Eötvös Loránd University, Budapest, Hungary
* Corresponding author: Dániel Horváth: daniel.horvath@sztaki.hu
|
|
|
|
|
|
|
Paper |
Results |
Presentation |
</Code> |
</Citation> |
Qualitative Evaluation
Abstract & Method
Even though reinforcement-learning-based algorithms achieved superhuman performance in many domains, the field of robotics poses significant challenges as the state and action spaces are continuous, and the reward function is predominantly sparse. In this work, we propose:
- HiER: The technique of highlight experience replay is a data exploitation curriculum learning (CL) method. Contrary to PER and HER, HiER creates a secondary experience replay buffer Bhier. HiER store transitions in Bhier based on certain criteria. The criteria can be based on any type of performance measure, in our case, the undiscounted sum of rewards (R) was chosen with a λ threshold that changes in time. If R > λ, the given episode is stored in Bhier. For updates, transitions are sampled both from the 'standard' experience replay Bser and Bhier according to a given sampling ratio ξ. It can be added to any off-policy actor-critic RL agent. If only positive experiences are stored in Bhier, then it can be viewed as a special, automatic demonstration generator as well.
- HiER+: The combination of HiER and an arbitrary data collection (traditional) curriculum learning method. The overview of HiER+ is depicted in Fig. 1. Furthermore, as an example of the data collection CL method, we propose E2H-ISE, that controls the entropy of the initial state-goal distribution H(μ0) which indirectly controls the task difficulty. ISE stands for initial state entropy. The advatage of the E2H-ISE method is that it is significantly easier to implement than the more sophisticated, state-of-the-art methods, while it is universal and requires minimal prior knowledge. Thus, the full potential of HiER+ can be presented conveniently with the E2H-ISE method.
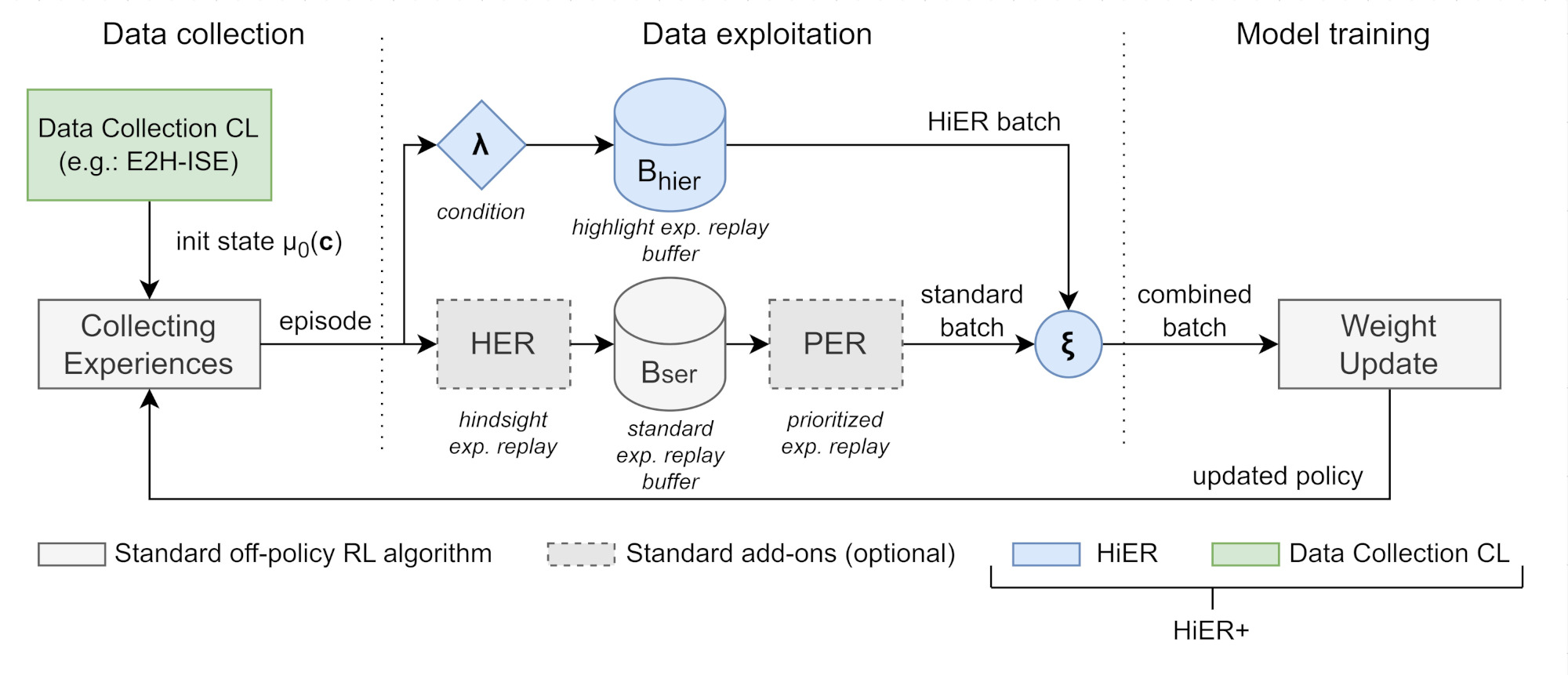
Fig. 1: The overview of HiER+.
Results
Our contributions were validated on 8 tasks of 3 robotic benchmarks:
- Firstly, HiER and HiER+ with E2H-ISE are thoroughly evaluated on the PandaPush-v3, PandaSlide-v3, and PandaPickAndPlace-v3 tasks of the PyBullet-based Panda-Gym robotic benchmark.
- Secondly, HiER is evaluated against HER on the FetchPush-v2, FetchSlide-v2, and FetchPickAndPlace-v2 tasks of the MuJoCo-based Gymnasium-Robotics Fetch robotic benchmark.
- Finally, HiER is tested on the PointMaze-Wall-v3 and PointMaze-S-v3 tasks of the MuJoCo-based Gymnasium-Robotics PointMaze environment which poses a fundamentally different challenge to the RL agent.
For the experiments SAC was utilized as base RL algorithm. For further details we refer the reader to the article.
Aggregated Results on All Tasks
Our experimental results show that the HiER versions significantly outperform their correspondiong baselines. Fig 2 shows the aggregated results across the 8 tasks in all metrics.

Fig. 2: Aggregated results on all tasks.
The performance profiles depicted on Fig 3 shows that HiER and HiER[HER] have stochastic dominance over their baselines.
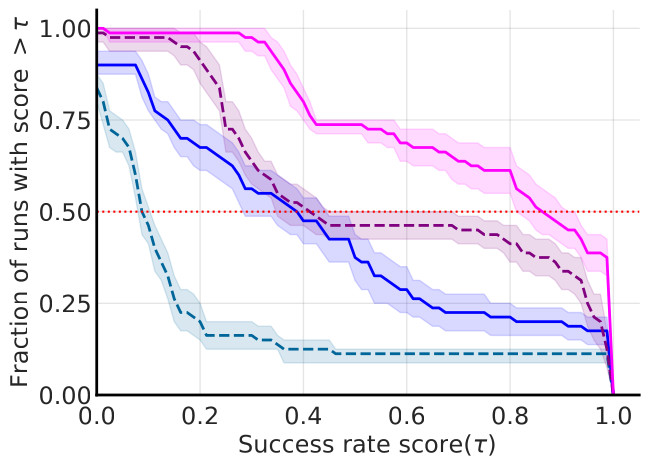

Fig. 3: Performance profiles.
Additionally, Fig 4 shows the probability of improvement.
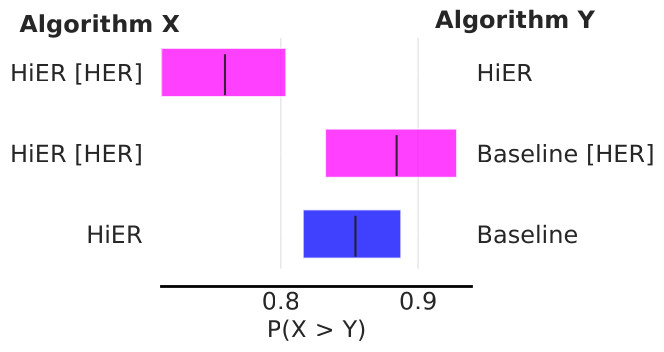
Fig. 4: Probability of improvement.
Panda-Gym
Our experimental results, presented on Fig 5-8 and in Tab. 1-3, show that the HiER significantly outperform the baselines. Additionally, HiER+ further improves the performance of HiER. E2H-ISE alone slightly improves the performance of the baselines.
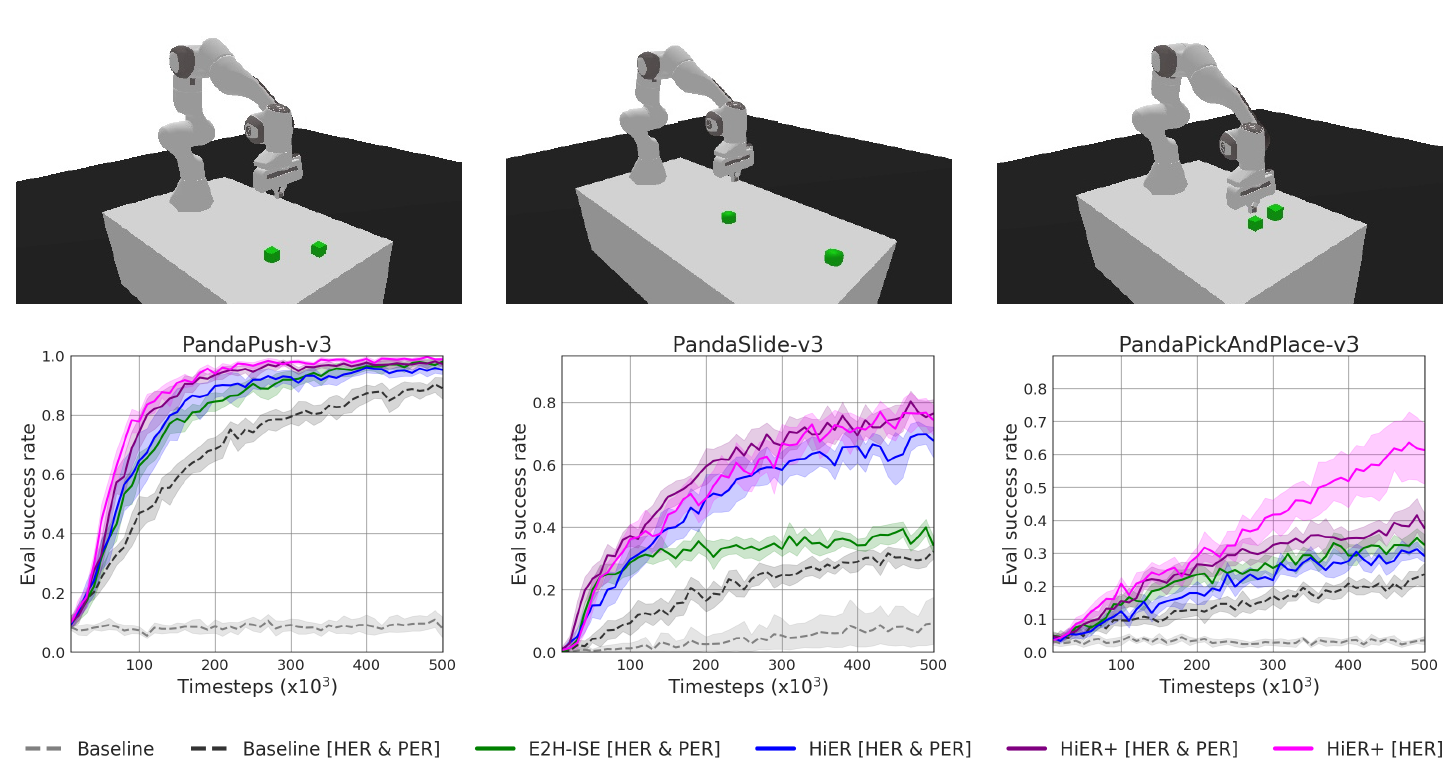
Fig. 5: The push, slide, and pick-and-place tasks of the Panda-Gym benchmark with the learning curves of selected algorithms.

Fig. 6: Aggregated results on the push, slide, and pick-and-place tasks of the Panda-Gym benchmark.
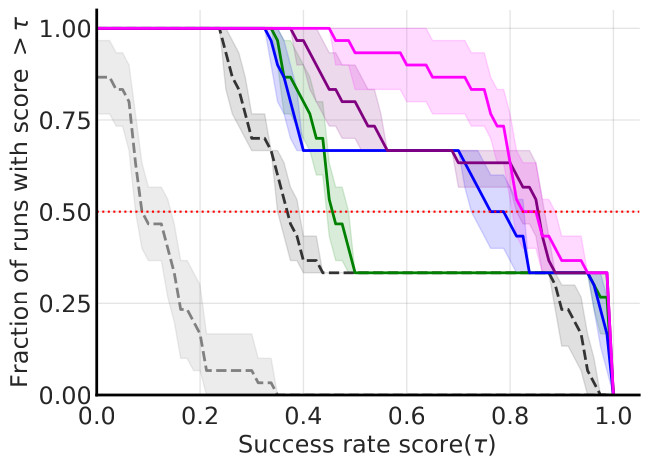

Fig. 7: Performance profiles on the push, slide, and pick-and-place tasks of the Panda-Gym benchmark.
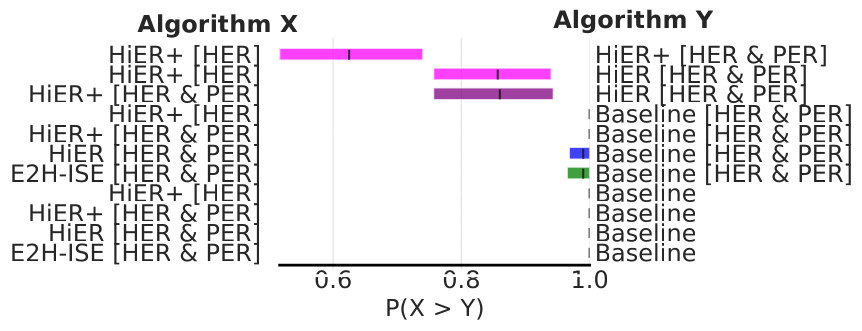
Fig. 8: Probability of improvement on the push, slide, and pick-and-place tasks of the Panda-Gym benchmark.
Tab. 1: HiER and HiER+ compared to the state-of-the-art based on success rates on the Panda-Gym robotic benchmark.

Tab. 2: HiER and HiER+ compared to the state-of-the-art based on success rates on the Panda-Gym robotic benchmark.

Tab. 3: HiER and HiER+ compared to the state-of-the-art based on accumulated reward on the Panda-Gym robotic benchmark.

Gymnasium-Robotics Fetch
Our experiment results are depicted in Fig 9-10. In all cases, a version of HiER yields the best score.
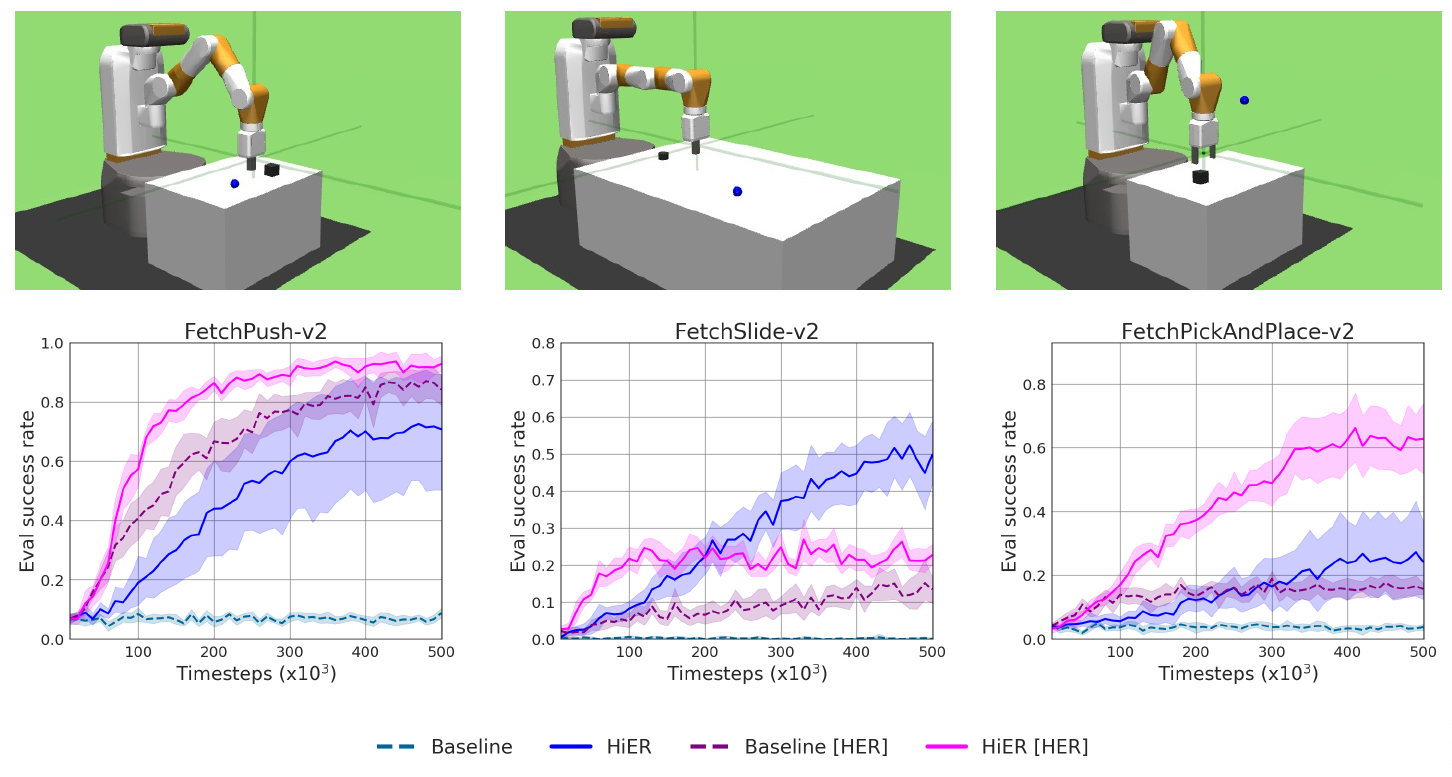
Fig. 9: The push, slide, and pick-and-place tasks of the Gymnasium-Robotics Fetch benchmark with the learning curves of selected algorithms.

Fig. 10: Aggregated results on the push, slide, and pick-and-place tasks of the Gymnasium-Robotics Fetch benchmark.
Gymnasium-Robotics PointMaze
Our experiment setup and the results are depicted in Fig 11-12.
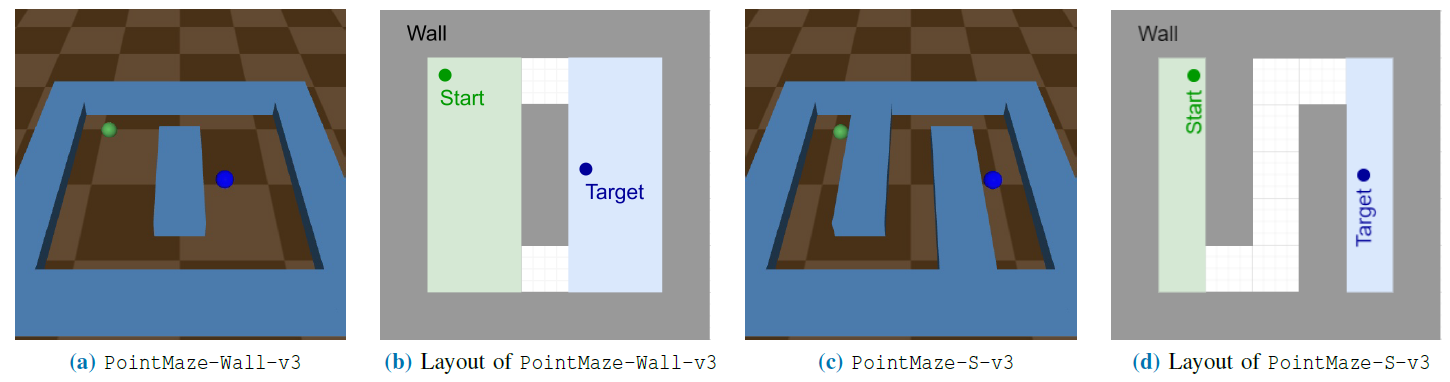
Fig. 11: The tasks of the Gymnasium-Robotics PointMaze benchmark.
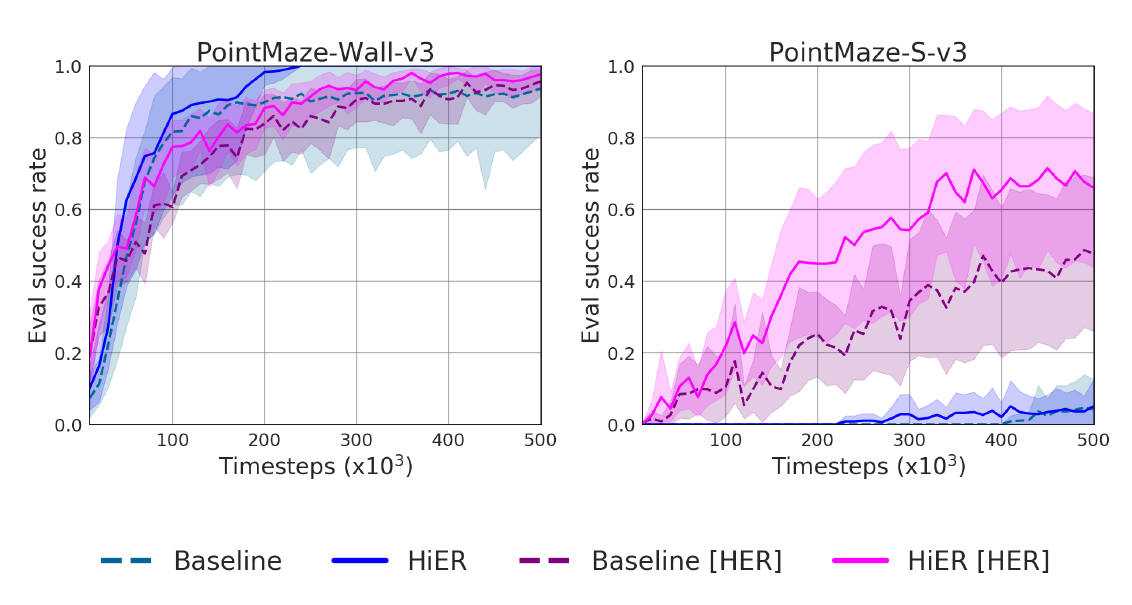
Fig. 12: The learning curves of the tasks of the Gymnasium-Robotics PointMaze benchmark.
HiER versions
Our results are depicted in Fig 13-15.
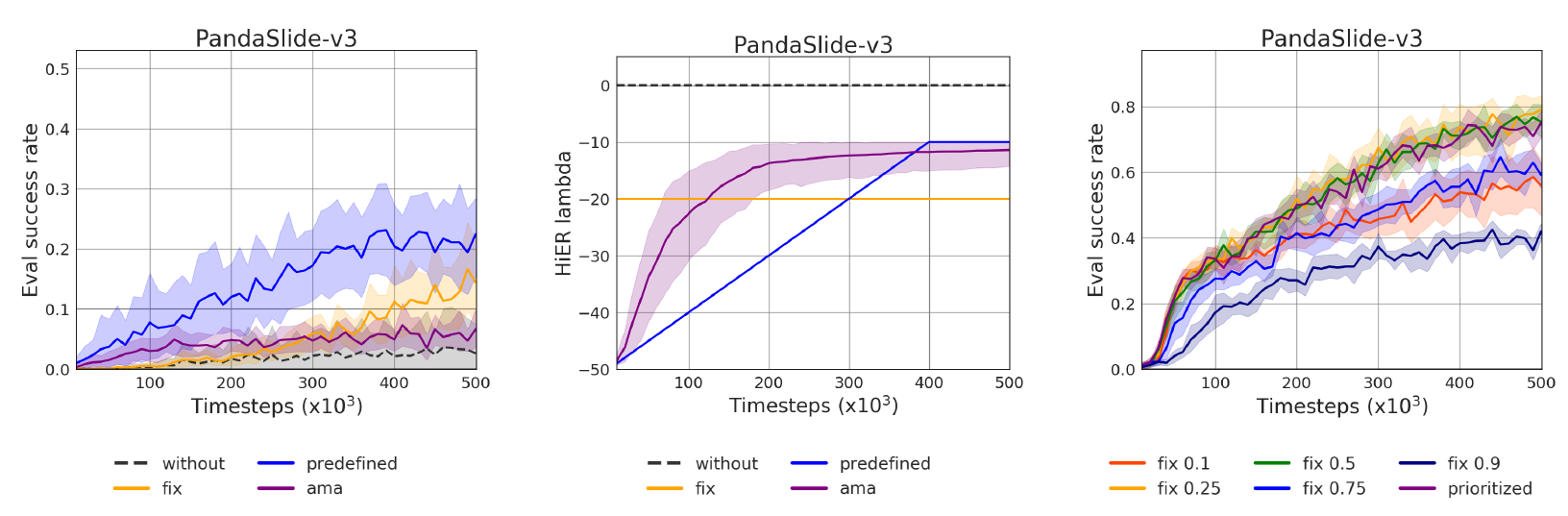
Fig. 13: The analysis of HiER versions.

Fig. 14: The different HiER λ methods on the slide task of the Panda-Gym benchmark.
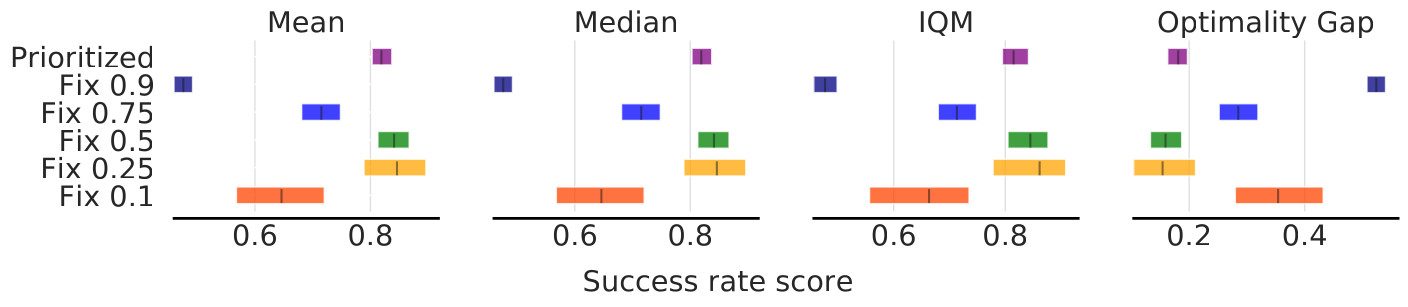
Fig. 15: The different HiER ξ methods on the slide task of the Panda-Gym benchmark.
E2H-ISE versions
Our results are depicted in Fig 16.
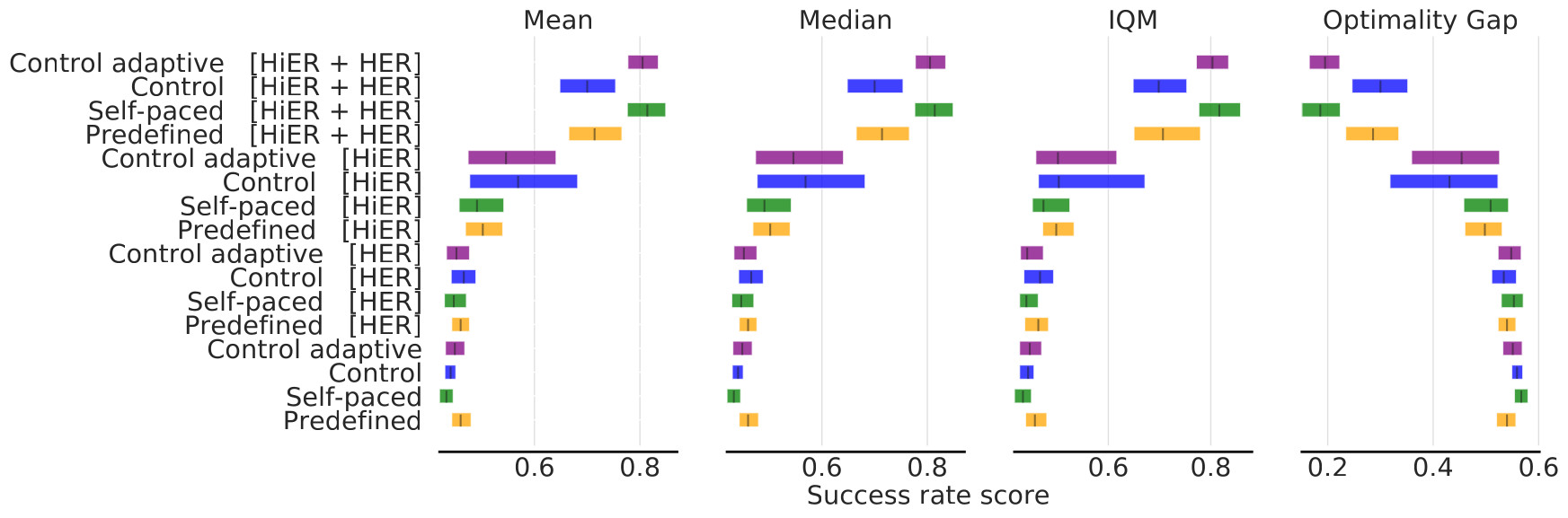
Fig. 16: The analysis of E2H-ISE versions on the slide task of the Panda-Gym benchmark.
TD3 and DDPG versions
Our results are depicted in Fig 17.

Fig. 16: HiER+ with DDPG and TD3 on the slide task of the Panda-Gym benchmark.
Presentation (4 + 3 mins)
Citation
@article{horvath_hier_2024,
title = {{HiER}: {Highlight} {Experience} {Replay} for {Boosting} {Off}-{Policy} {Reinforcement} {Learning} {Agents}},
volume = {12},
issn = {2169-3536},
shorttitle = {{HiER}},
url = {https://ieeexplore.ieee.org/document/10595054},
doi = {10.1109/ACCESS.2024.3427012},
urldate = {2024-07-26},
journal = {IEEE Access},
author = {Horváth, Dániel and Bujalance Martín, Jesús and Gàbor Erdos, Ferenc and Istenes, Zoltán and Moutarde, Fabien},
year = {2024},
note = {Conference Name: IEEE Access},
keywords = {Training, Robots, robotics, Task analysis, Standards, Reinforcement learning, reinforcement learning, Curriculum learning, Process control, Data collection, experience replay, Random variables, Curriculum development},
pages = {100102--100119},
}