Object Detection Using Sim2Real Domain Randomization for Robotic Applications





1 Institute for Computer Science and Control, Hungarian Research Network, Budapest, Hungary
2 CoLocation Center for Academic and Industrial Cooperation, Eötvös Loránd University, Budapest, Hungary
3 Department of Manufacturing Science and Engineering, Budapest University of Technology and Economics, Budapest, Hungary
4 Institute of Computer Science, Faculty of Science, Pavol Jozef Šafárik University, Košice, Slovakia
* Corresponding author: Dániel Horváth: daniel.horvath@sztaki.hu
|
|
|
|
|
|
Paper |
ICRA23 |
</Code> |
</Citation> |
Presentation
Abstract & Method
We propose a sim2real transfer learning method based on domain randomization for object detection (S2R-ObjDet) with which labeled synthetic datasets of arbitrary size and object types can be automatically generated. Subsequently, an object detection model is trained to detect the different types of industrial objects. With the proposed domain randomization method, we could shrink the reality gap to a satisfactory level, achieving 86.32% and 97.38% mAP50 scores respectively in the case of zero-shot and one-shot transfers, on our publicly available manually annotated InO-10-190 dataset, containing 190 real images of 920 object instances of 10 classes. The class selection was simultaneously based on different and similar objects in order to test the robustness of the model in terms of detecting different classes and differentiating between similar objects. Our solution fits for industrial use as the data generation process takes less than 0.5s per image and the training lasts only around 12h, on a GeForce RTX 2080 Ti GPU. Furthermore, the model can reliably differentiate similar classes of objects by having access to only one real image for training. To our best knowledge, this was the first work satisfying these constraints. Moreover, we proposed a novel evaluation metric, named generalized confusion matrix (GCM) which is an adaptation of the traditional confusion matrix to object detection. It offers a solution to the shortcomings of the classical precision-recall-based mAP and f1 score. With GCM, the misclassification error can be quantified and evaluated.
Our contributions are as follows.
- Our novel sim2real domain randomization method for object detection (S2R-ObjDet) which describes the data generation process, and our sim2real training pipeline.
- Our InO-10-190 dataset, which is a real-world dataset of 190 manually annotated images (RGB and depth) containing 920 objects of 10 classes that address the problem of high class similarity to validate our method. The dataset is publicly available alongside our code and can serve as a benchmark for object detection algorithms.
- For evaluation, we introduced the generalized confusion matrix (GCM) which is an altered version of the traditional confusion matrix fit to object detection. It proved to be extremely useful for detecting and quantifying misclassifications which is the primary cause of performance loss in the case of similar classes.
- A real-world robotic implementation of the method as a proof of concept containing an ROS-based robot control system.
- Our implementations of our sim2real data generation and training module, and our robot control framework. Both can be used as out-of-the-box software modules for industrial robotic applications.
- We achieved 86.32% mAP50 and 97.38% mAP50 scores in zero-shot and one-shot transfers that show the usability of our methods even in the case of an industrial application where high reliability is crucial.
- Our experiments show that having even only one sample image from the target domain significantly improves the model’s performance for similar classes.
- A thorough ablation study focusing on finding the key factors of the data generation process.
The main problem we tackle is how to transfer knowledge efficiently from simulation to the real world in the case of object detection. Additional challenges arise from the following circumstances.
- Having no or only one image from the real world.
- Having industrial objects that share similar features, thus, it is more challenging to classify them (Fig. 6).
Sim2real object detection is a special case of transfer learning: instead of real images obtained from the target domain, the model is trained on synthetic data (images from source domain), DS ≠ DT. While, the source task and the target task are the same, TS = TT. Nevertheless, the model trained on synthetic data, ceteris paribus, does not work on real images as the domains are disparate. This phenomenon is referred to as the reality gap, and the main goal of sim2real transfer is to bridge this gap. In our case, the sim2real transfer is the second phase of the knowledge transfer, shown in Fig. 1.
Fig. 1. Different phases of knowledge transfer.
The flowchart diagram of our data generation, training, and evaluation process is depicted in Fig. 2. It can be broken down into functionally separable tasks. The data generation process creates randomized and postprocessed synthetic images of given objects. It also automatically generates the annotations for the images. Thus, the output of the data generation process is a set of images paired with their labels grouped into a training and a validation dataset.
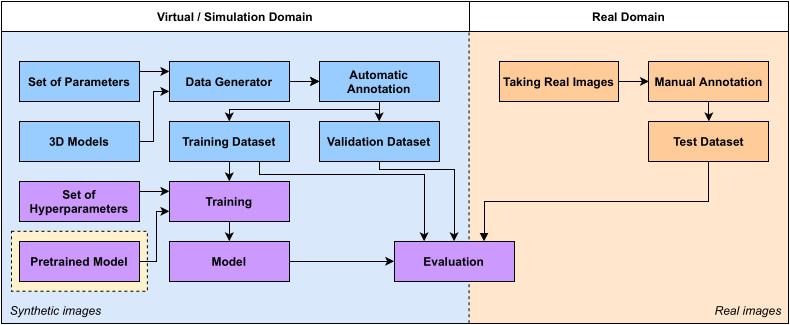
Fig. 2. Flowchart diagram of our data generation, training, and evaluation process. The blue and orange boxes depict the data generating and data gathering steps. The purple boxes represent the steps of training and evaluation.
The data generation process is responsible for the creation of synthetic images paired with accurate automatic ground-truth annotations. In several stages of this process, artificial random perturbations are applied as domain randomization techniques, such as in the case of object number, classes, placement, color, texture (Fig. 3), and once the image is rendered, our postprocess transformation is applied (Fig. 4).

|

|
| Fig. 3. Some examples of textures. | Fig. 4. Postprocess transformation on a blank image. |
Two examples of synthetic images with the automatically generated annotations are depicted in Fig. 5 and Fig 6. The bounding boxes are shown here for illustration purpose only.

|

|
| Fig. 5. Generated synthetic image. | Fig. 6. Generated synthetic image. |
Furthermore, we adapt the confusion matrix measure from the field of image classification to object detection and use it as an additional performance measure. The adaptation works as described as follows.
- Adding an extra row and an extra column to the classical confusion matrix. Thus, there are c +1rows and columns, where c is the number of classes. The additional column represents the objects that are not predicted to any of the classes but actually belong to one class. On the other hand, the additional row of the matrix represents the cases when the model predicted an object of a class in a position where there should not be any object.
- The values of the diagonal are the correct predictions. For simplicity, the last element of the diagonal is zero. This element should contain the number of objects that are not in the images and the model rightfully did not find them, which does not have any meaning.
- As more than one prediction can belong to one groundtruth object, a given ground-truth object appears in the matrix as many times as many predictions are paired with it. Therefore, contrary to the traditional confusion matrix, the sum of all elements in the matrix will not necessarily be equal to the sum of all ground-truth objects or predictions.
Dataset
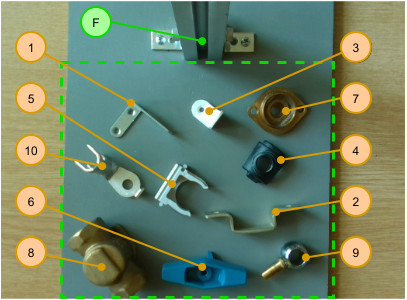
Ten industrial parts were selected for the dataset. Object diversity as well as object similarity were the two major points of consideration. The former helps us to evaluate the detection performance of the model for various types of objects, whereas the latter is important in assessing the classification performance of the model. The industrial parts are depicted in Fig. 7. Their names in order of their identifier numbers are the following: 1. L-bracket, 2. U-bracket, 3. angle bracket, 4. seat, 5. pipe clamp, 6. handle, 7. bonnet, 8. body, 9. ball, 10. cable shoe. The letter “F” designates the camera holder frame. The green dashed lines show the borders of the cropped images.
As it can be seen, on one hand, objects of different sizes, shapes, colors, and materials were selected to increase diversity. On the other hand, some objects share similar characteristics, such as circular holes. Furthermore, two parts, the bonnet (#7) and the body (#8) were chosen because of their high level of similarity, as shown in Fig. 8.
|

|
| Fig. 7. Selected industrial parts for the dataset. | Fig. 8. Similarity of the body and the bonnet objects. |
Results
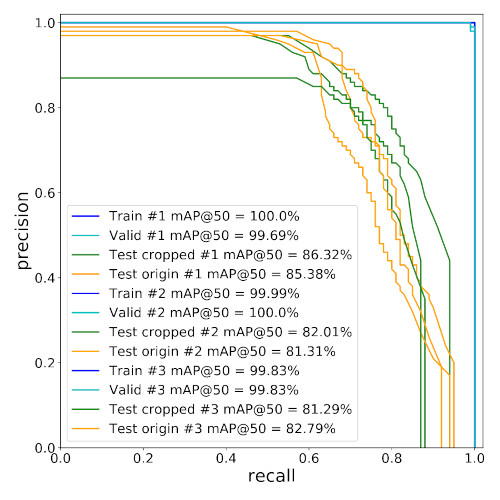
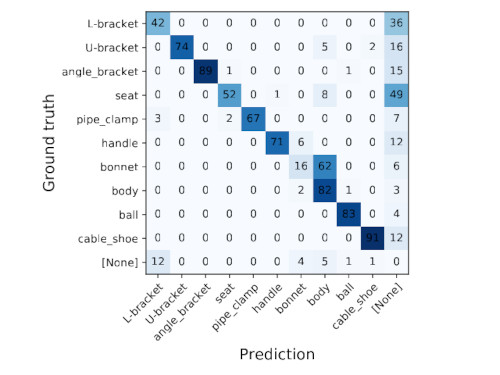
The best-performing zero-shot transfer model achieved 86.32% mAP50 on the cropped test dataset with 4000 synthetic images and without any real image. The results of zero-shot transfer are depicted in Fig. 9 and 10.
|
|
| Fig. 9. The precision-recall curves. | Fig. 10. The confusion matrix. |
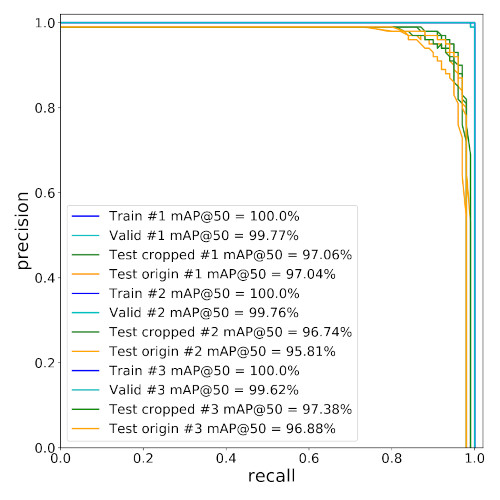
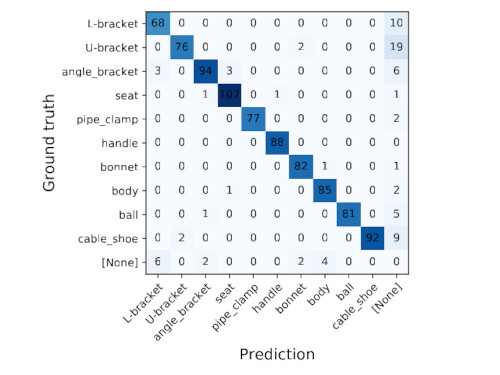
The best-performing one-shot transfer model achieved 97.38% mAP50 on the cropped test dataset with 2000 synthetic images and one real image (multiplied 2000x). The results of zero-shot transfer are depicted in Fig. 11 and 12.
|
|
| Fig. 11. The precision-recall curves. | Fig. 12. The confusion matrix. |
For qualitative evaluation, Fig. 13 and 14 shows an accurate prediction and an inaccurate solution. In the latter case, the distractor objects resembling a body object in main characteristics could mislead the model, implying that the model learned an overly general representation of the object. As the quantitative results show, the vast majority of examples is accurate.

|

|
| Fig. 13. An accurate example. | Fig. 14. An inaccurate example. |
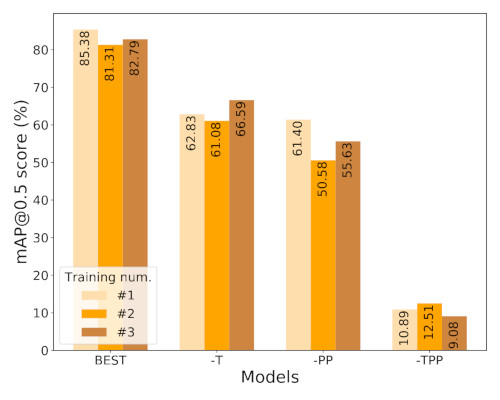
Two important factors in our domain randomization method are the random textures of the objects and the postprocessing method. We have generated datasets without these factors. The results are shown in Fig. 15. Both the added texture and the postprocessing methods contribute significantly to the performance. Without the added texture, the performance drops to 63.50% and 74.71% mAP50 in the case of the original and the cropped images. Without postprocessing, the performance is only 55.87% and 60.42% mAP50, respectively. Finally, the performance decreases drastically achieving 10.83% and 13.81% mAP50 without the two methods. These experiments show how essential these types of domain randomization methods are.
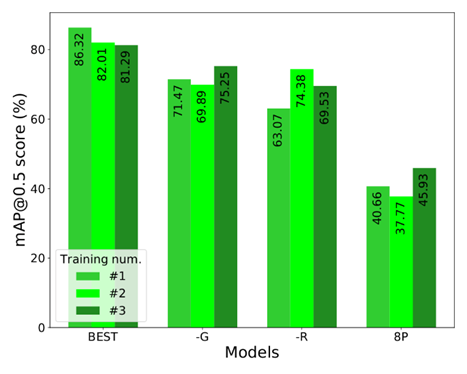
Furthermore, the effect of simulated gravity, the effect of random disturbance around the grid positions, and the effect of replacing the all-point bounding box calculation with the 8-point bounding box calculation are measured as well, depicted in Fig. 16. All of the aforementioned factors have a relevant effect on the performance. In the case of bounding box calculation, the performance drops with the less tight BBs, implying two reasons. First, the ground-truth BBs are tight, thus computing the IOU50 with less tight BBs may result in many discarded matches. Second, in the crowded images, the BBs are too extensive, thus, they could significantly overlap each other which may confuse the model.
|
|
| Fig. 15. Results of the ablation study with zero-shot transfer. Model without added textures (-T), without postprocessing methods (-PP), and without both (-TPP). | Fig. 16. Results of the ablation study with zero-shot transfer. Without simulated gravity (-G), without random disturbance (-R), and with the 8-point bounding box calculation (8P). |
Citation
@article{horvath_sim2real_obj_2023,
title = {Object {Detection} {Using} {Sim2Real} {Domain} {Randomization} for {Robotic} {Applications}},
volume = {39},
issn = {1941-0468},
doi = {10.1109/TRO.2022.3207619},
url = {http://doi.org/10.1109/TRO.2022.3207619},
journal = {IEEE Transactions on Robotics},
author = {Horváth, Dániel and Erdős, Gábor and Istenes, Zoltán and Horváth, Tomáš and Földi, Sándor},
month = apr,
year = {2023},
pages = {1225--1243},
}